About TAPAS
TAPAS is a table parsing model developed by Google Research. "TAPAS" is an acronym for "TAble PArSing," indicating the model's specialty.
TAPAS is unique because it's designed to understand tables as a structured form of data, and it's capable of performing tasks that require a combination of natural language understanding and reasoning over tabular data.
TAPAS is based on the BERT (Bidirectional Encoder Representations from Transformers) architecture,
which is a popular and highly effective language model developed by Google.
Like BERT, TAPAS is a transformer-based model, but with a twist: it treats tables as a type of language.
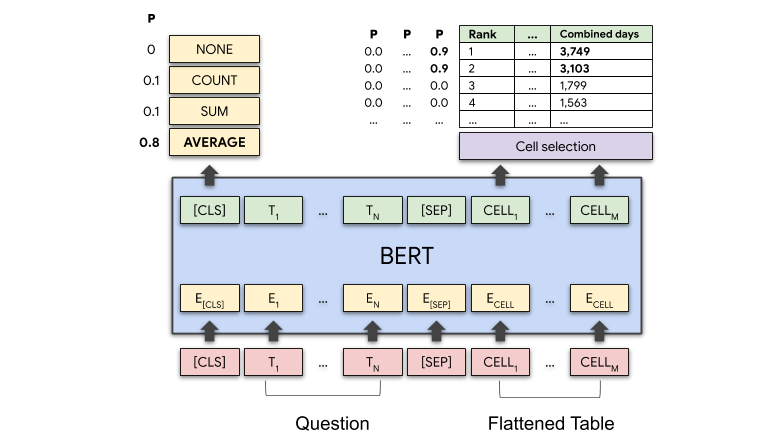
TAPAS reads the entire table cell-by-cell, row-by-row, including the column headers,
then relates the content of the cells to the question being asked, making it possible for TAPAS to
perform tasks that require understanding of the table's content.
TAPAS can be used in a variety of tasks related to tables, including but not limited to:
- Table-based Question Answering: Given a natural language question referring to a table, TAPAS can select the correct cell or cells that contain the answer.
- Table completion: Given a table with some missing cells, TAPAS can predict the missing values.
- Tabular summarization: TAPAS can generate a text summary of the table's content.
The following image shows the TAPAS architecture
TAPAS for the enterprise
Given its ability to understand and reason over tabular data, TAPAS could be useful in many business scenarios that involve tables, such as financial statements, product catalogs, project management timelines, and more.
Here are a few possible applications for TAPAS in an enterprise setting:
- Data Analysis and Reporting: TAPAS can be used to extract insights from financial reports, sales data, customer demographics, and other types of business data that are often represented in tabular form. For instance, you could ask TAPAS to answer questions like "Which product had the highest sales last quarter?" or "What is the total revenue generated from Region X?"
- Customer Support: In the context of customer support, TAPAS can be employed to pull data from tables in a database to answer customer queries. For example, a customer might ask, "When is my product due for delivery?" TAPAS could then find the relevant delivery schedule and provide the requested information.
- Ridge Regression: This is a type of linear regression that introduces a small amount of bias (known as regularization) into the regression estimate, which can lead to substantial reductions in variance and improved prediction accuracy.
- Automated Document Processing: Many business documents, such as invoices, contracts, and technical specifications, often contain tables. TAPAS can extract and process this information, making document processing more efficient.
- Business Intelligence: TAPAS can be used to build more intuitive business intelligence tools. Users can ask natural language questions about their data, and TAPAS can parse the tables in the database to provide the answers.
- Data Quality Management: TAPAS can potentially be used to detect errors or anomalies in tabular data, by checking for inconsistencies between related cells or identifying cells that do not fit the expected patterns.
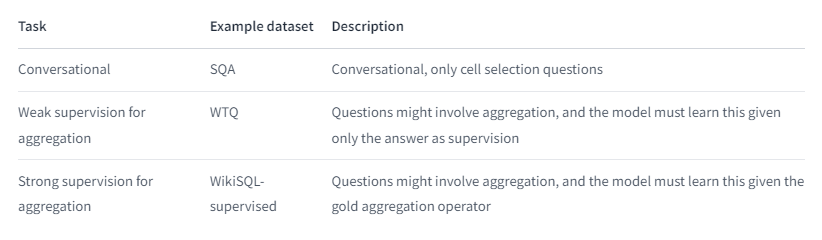
TAPAS has been fine-tuned on several datasets
- SQA: Sequential Question Answering by Microsoft
- WTQ: Wiki Table Questions by Stanford University
- WikiSQL: by Salesforce
The general steps for TAPAS solution
The general process can involve a couple of steps:
- Data Extraction: First, the relevant information from the tables needs to be extracted and prepared for processing. This could involve deciding which columns or rows are relevant to the text to be generated.
- Text Generation: The extracted data is then processed by the pre-trained language model, which generates the corresponding text. The model might use the table's headers and data values as inputs and then generate a sentence or paragraph that accurately represents that information in natural language.
- Fine-tuning: Often, a pre-trained model is fine-tuned on a specific task to optimize its performance. For table-to-text generation, the model could be fine-tuned on a dataset of tables and corresponding text descriptions.
Pre-trained models have already shown remarkable results in various tasks, and their application in table-to-text generation is promising. However, challenges still exist, such as generating text that accurately represents complex tables or dealing with tables that have missing or erroneous data.
Fine-tuning with the business dataset
The general process can involve a couple of steps how we can fine-tune with the business dataset:
- STEP 1: Choose one of the 3 ways in which business can use TAPAS
- STEP 2: Prepare the data in the SQA format
- STEP 3: Convert the data into tensors using TapasTokenizer
- STEP 4: Train (fine-tune) the model
Example
TAPAS is designed to interpret and provide answers from tabular data, which are structured in a tabular format like spreadsheets or database tables.
| Actors | Age | Number of movies |
|---|
| Brad Pitt | 56 | 87 |
| Leonardo Di Caprio | 45 | 53 |
| George Clooney | 59 | 69 |
Here comes the result with TAPAS
How many movies has George Clooney played in? -- 69
How old is Brad Pitt? -- 56
TAPAS extends the functionality of language models by allowing them to understand and interact with structured tabular data, which is a significant part of information in the business world.

Want to build your Enterprise AI Solution
Please fill out the form. One of our staff will reach out to you as soon as possible and discuss the process to build your Enterprise AI Solution.
Contact Us
