
Intelligent Resume Rules-based Matching System
With CubeDrive's AI resume matching solution, organizations can easily automate resume matching based on customized academic backgrounds, technical expertise, and other criteria.
Request a demo
Overview
Resume Matching with Rule-Based Solutions
Resume matching via rule-based solutions offers a deterministic framework for ranking candidates. By applying predefined logic to resume data and job specifications, the system automatically identifies top talent by combining:
- Large Language Models (LLMs) for resume understanding and structured data extraction.
- A configurable, rule-based matching engine for transparent and controllable decision-making.
- Score-based ranking to surface the best matches with clear reasons.
How It Works
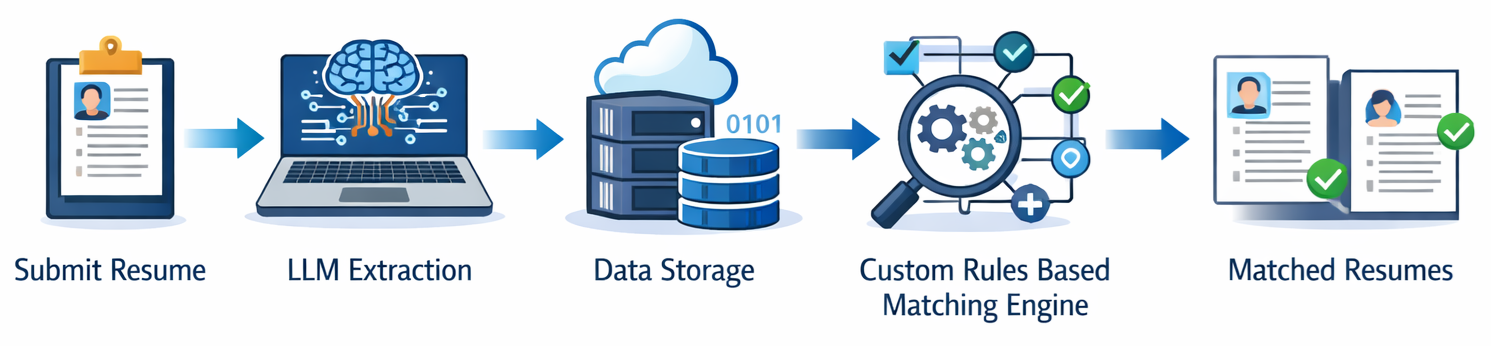
The Resume Matching System bridges the gap between unstructured resumes and intelligent, explainable matching decisions. CubeDrive's rule-based resume matching process follows these steps:
Matching Rules
Matching Rules: Clear, Explainable, and Configurable
The core strength of the system lies in its rule-based matching model, which is divided into three logical layers.
1: Hard Rules Mandatory Filters
Hard rules determine eligibility. If a candidate fails any hard rule, they are immediately excluded before any scoring takes place.
Key Examples:
- Candidate's highest degree must be equal to or higher than a bachelor's degree
- Candidate must share at least one common language
- Candidate must have specific professional domains
2: Score Rules Ranking Logic
Once a candidate passes all hard rules, score rules determine how good the match is. Each rule defines a specific condition and assigns a quantitative value.
Scoring Breakdown:
- Specific city -> +20 points
- Technical skill match -> +25 points
- Professional background similarity -> up to +25 points
- Research field alignment -> up to +35 points
3: Business Rules Domain-Specific Enhancements
Business rules allow organizations to inject context-specific logic without changing core matching behavior, making the system highly adaptable.
Context-Specific Examples:
- Similar work experience (vector similarity >= threshold) -> +30 points
Adapts to different industries, employers, and advisors.
Rule Configuration
Rule Configuration via YAML
All matching rules are defined in external YAML configuration files, not hard-coded logic.
matching_rules.yaml
- name: "shared_alumni"
description: "Teacher and student attended the same university"
condition: "student.alumni_id == teacher.alumni_id"
weight: 20
type: "bool"
- name: "research_alignment"
description: "Alignment based on research field keywords"
condition: "jaccard_similarity(student.research, teacher.research)"
weight: 35
type: "compare"
Agility
Business teams can adjust weights and behavior without a developer deployment.
Scalability
Add new rule categories easily as the platform grows.
Versatility
Run different matching scenarios (teachers, employers, advisors) using the same engine.
Conclusion
This Resume Matching System combines LLM-powered data extraction with a declarative, rule-driven engine to deliver accurate, explainable, and customizable matching results.
It is designed not just to find matches, but to justify them clearly, adapt to evolving business rules, and scale across different use cases.

Ready to build your custom AI solutions?
Please fill out the form below to explore your organization's potential. A member of our strategy team will reach out shortly to discuss your specific goals.
Contact Us