
Give a try Hire our team


What is LLMs
Large Language Models (LLMs) are foundation models that utilize deep learning in natural language processing (NLP) and natural language generation (NLG) tasks. They are designed to learn the complexity and linkages of language by being pre-trained on vast amounts of data. This pre-training involves techniques such as fine-tuning, in-context learning, and zero/one/few-shot learning, allowing these models to be adapted for certain specific tasks. They have the ability to understand context, generate human like text and perform different tasks.
Why do LLMs matter to Enterprises?
LLMs are the powerful tool for the organization to enhance customer experiences and provides valuable insights from unstructured data.
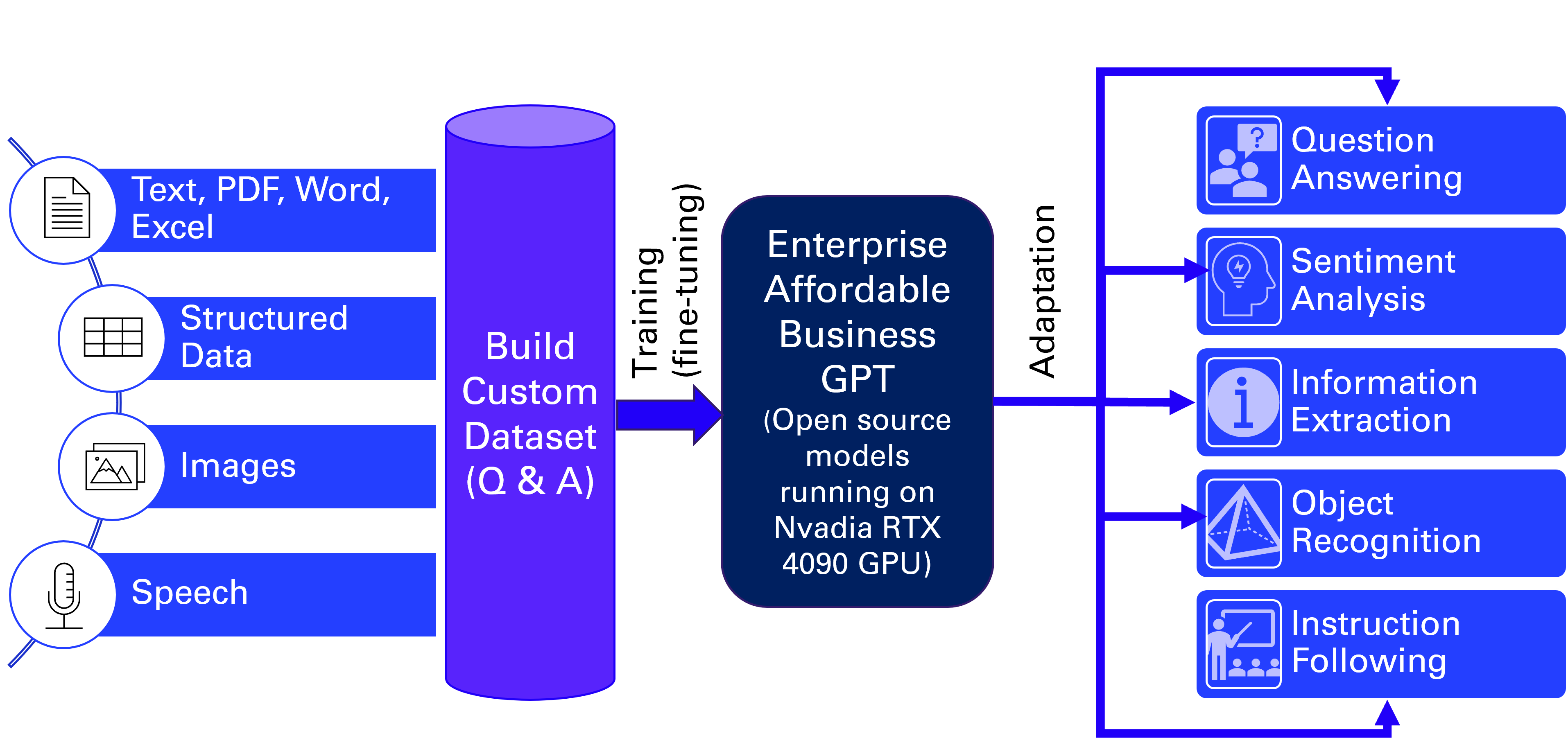
Developing An LLM Strategy
Key steps in developing an LLM strategy include:
Most popular Enterprise LLM Models
| LLM | Company | Description |
|---|---|---|
| BERT | Bidirectional Encoder Representations from Transformers (BERT) is a family of language models introduced in 2018 by researchers at Google. BERT is based on the transformer architecture. | |
| RoBERTa | Robustly-optimized BERT approach (RoBERTa) introduced by the Facebook. It based on the google BERT. RoBERTa includes additional pre-training improvements that achieve state-of-the-art results on several benchmarks, using only unlabeled text from the world-wide web, with minimal fine-tuning and no data augmentation. | |
| LLaMA | Meta | LLaMA (Large Language Model Meta AI) is a large language model (LLM) released by Meta AI in February 2023. A variety of model sizes were trained ranging from 7 billion to 65 billion parameters. |
There still have lots of other models, such as: ALBERT, ELECTRA, DistilBERT, XLNet, T5, ChatGLM etc。
Criteria for choose an LLM
The following lists the criteria for the enterprise to choose a suitable LLM
Steps for an LLM training
Training an AI large language model (LLM) like LLaMA involves several key steps:
Training large language models require significant computational resources, as well as careful monitoring to ensure they're learning in a way that's ethical and aligned with human values. If you do not have enough resources and experience to train your own LLMs, you can consider using pre-trained models or third-party APIs.
General dataset and format
1: SQuAD (Stanford Question Answering Dataset)
SQuAD is a widely used deep learning question-answering dataset.SQuAD focuses on the task of question answering. It tests a model’s ability to read a passage of text and then answer questions about it. The SQuAD dataset is typically in JSON format and includes the following fields:
- context: paragraph content. - qas: a set of questions and answers. - question: the content of question. - id: the identify of the question. - answers: A list of answers - text: the content of answer. - answer_start: the start position of the answer.
The following example lists the JSON data format which based on the SQuAD data.
{
"version": "1.1",
"data": [{
"title": "Super Bowl 50",
"paragraphs": [{
"context": "Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24-10 to earn their third Super Bowl title.",
"qas": [{
"question": "Which NFL team won Super Bowl 50?",
"id": "56be4db0acb8001400a502ec",
"answers": [{
"text": "Denver Broncos",
"answer_start": 163
}]
},
{
"question": "What was the score of Super Bowl 50?",
"id": "56be4db0acb8001400a502ed",
"answers": [{
"text": "24-10",
"answer_start": 189
}]
}]
}]
}]
}
2. Stanford Alpaca: alpaca_data.json
It contains 52K instruction-following data we used for fine-tuning the Alpaca model. This JSON file is a list of dictionaries, each dictionary contains the following fields:
This is the an example JSON data:
[{
"instruction": "Rewrite the following sentence in the third person",
"input": "I am anxious",
"output": "She is anxious."
}]
There are some other datasets and formats, you only need to find the format required by the model you choose, or you can do your own proprietary dataset according to the format required by the model and business.
Fine-tuning
Please refer to the relevant resources such as Huggingface Models, Huggingface Transformers Examples and the corresponding GitHub repository of the model, as well as documentation for PyTorch and TensorFlow to train a small model for your specific business needs.
Local Deployment
If you need to deploy and use your own trained small model locally, please refer to the relevant documentation on Huggingface Models, Huggingface Transformers, he corresponding GitHub repository of the model, as well as documentation for PyTorch and TensorFlow.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a well-known pre-trained language model developed by researchers at Google in 2018. BERT is an open source machine learning framework for natural language processing (NLP). BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context.
BERT is based on Transformers, a deep learning model in which every output element is connected to every input element, and the weightings between them are dynamically calculated based upon their connection. Using this bidirectional capability, BERT is pre-trained on two different, but related, NLP tasks: Masked Language Modeling and Next Sentence Prediction.
BERT is pre-trained on a massive amount of text data from wiki. During pre-training, BERT learns to predict masked words in sentences and determine the next sentence in a pair. This process helps BERT learn contextual representations of words.
After pre-training, BERT is fine-tuned on specific NLP tasks such as sentiment analysis, abstract summarization, question answering, etc., to adapt to specific tasks. Fine-tuning involves training BERT on labeled data specific to the task, allowing it to specialize for the task. This transfer learning approach enables BERT to leverage its general language understanding capability and apply it to various NLP tasks without requiring extensive task-specific training.
Many organizations are fine-tuning the BERT model architecture with supervised training to either optimize it for efficiency or specialize it for certain tasks by pre-training it with certain contextual representations.
RoBERTa
RoBERTa (Robustly Optimized BERT approach) is an improved and optimized version of BERT, proposed by Facebook AI in 2019. The goal of RoBERTa is to enhance the performance of BERT by using a larger model size, longer training time, and richer data.
Some of the improvements in RoBERTa compared to BERT include:
These improvements in RoBERTa result in significant performance gains across various natural language processing tasks. It surpasses BERT in many benchmark tests and achieves state-of-the-art results in several NLP competitions.
LLaMA
LLaMA(Large Language Model Meta AI) is a collection of state-of-the-art foundation language models ranging from 7B to 65B parameters. These models are smaller in size while delivering exceptional performance, significantly reducing the computational power and resources needed to experiment with novel methodologies, validate the work of others, and explore innovative use cases.
LLaMA, an auto-regressive language model, is built on the transformer architecture. Like other prominent language models, LLaMA functions by taking a sequence of words as input and predicting the next word, recursively generating text.
In terms of performance, LLaMA shows its impressive capabilities. The LLaMA model with 13 billion parameters can better perform than GPT-3 (which has 175 billion parameters) on most benchmarks, and it can run on a single V100 GPU. Furthermore, the largest LLaMA model with 65 billion parameters can rival Google's Chinchilla-70B and PaLM-540B models.
Here lists various improved models based on LLaMA that have been fine-tuned for specific tasks or applications.
| LLM | Company | Description |
|---|---|---|
| Alpaca+LoRA | Stanford University | Alpaca is an AI language model developed by a team of researchers from Stanford University. It uses LLaMA, which is Meta's large-scale language model. It uses OpenAI's GPT (text-davinci-003) to fine-tune the 7B parameters-sized LLaMA model. |
| Vicuna | UC berkeley、CMU、Stanford | Vicuna is an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. It is an auto-regressive language model, based on the transformer architecture. |
| Koala | Berkeley AI Research Institute (BAIR) | Koala is a version of LlaMA fine-tuned on dialogue data scraped from the web and public datasets, including high-quality responses to user queries from other large language models, as well as question-answering datasets and human feedback datasets. |
| Guanaco+QLoRA | University of Washington | Guanaco is an advanced instruction-following language model built on Meta's LLaMA 7B model. It enables the fine-tuning of large language models on a single GPU. |
